We have updated the content of our program. To access the current Software Engineering curriculum visit curriculum.turing.edu.
Data Structures and Algorithms
aka “Data Structures Obstacle Course”
Learning Goals
- Introduce you to a few programming algorithms & data structures
- Spark your curiosity to further explore these concepts
- You may see these concepts as part of your interview process
Sorting Algorithms
Sorting algorithms are used to organize an array or list of elements. For example, if you have a list of words and they need to be arranged in alphabetical order, or arranging numbers from least to greatest.
There are multiple different methods for sorting the information depending on how the elements are broken up or compared to other elements. Here you can find a list of various sorting algorithms; however, we are only going to look into three sorting algorithms.
Bubble Sort
Bubble sort is completed by iterating over each element and comparing it to the next adjacent element and then swapping places if the elements are not in the correct order. It repeats this process until all elements in the array are sorted.
Bubble Sort Gone Wrong</summary>
</details>
Bubble Sort Visual</summary>
 </details>
</details>
Think About It
- How long would it take to complete a bubble sort?
- Write pseudo code for how you might sort this array
[7, 3, 4, 9].
Pseudo Solution
Review Solution</summary>
- Starting Array [7, 3, 4, 9]
- Find length of Array
- Compare each adjacent element until end is reached
- Start with index 0 and continue until last index equals array
length -1
- If element with smaller index is greater swap elements
- Repeat process until array is sorted
</details>
Insertion Sort
Insertion sort is done by sectioning the list or array into sorted and unsorted sections. Elements are then taken from the unsorted section and inserted into the correct position in the sorted section. The current element is compared to the prior element. The value that is greater is then shifted forward to make room for the smaller element.
Insertion Sort Visual</summary>
 </details>
</details>
Think About It
- How long would it take to complete an insertion sort?
- How does insertion sort compare to bubble sort?
Merge Sort
Merge sort takes the divide and conquer approach to sorting the list or array of elements. The array is continually split until only single elements of the array remain. Then the elements are compared to one another and merged in chunks. Once the elements have been broken into multiple single element arrays, the elements are then compared to make paired arrays. This process will continue by comparing the first element of the array to the first element of the other array until all the chunks are broken and combined to form a single array.
Merge Sort Visual</summary>
 </details>
</details>
Think About It
- How long would it take to complete a merge sort?
- How does this sort compare to bubble and insertion?
Data Structures
A data structure encompasses how the data is organized, managed, and what actions can be performed on the data. There are multiple types of data structures in programming and in order to determine the type of structure to use you might start by asking the following questions:
- How does the data need to be stored?
- The size of the data might help determine the answer to this question.
- What is the relationship between the elements of the data?
- How is the data used? What type of operations need to be performed to the data?
We are only going to explore some data structures, binary tree, linked list, and hash maps.
Binary Trees and Linked Lists are both “node” based data structures, where each piece of data is a “node” which contains a value of some kind and a reference to one or more “next” nodes; the first node in a both is typically called the ‘head’ or ‘root’ node.
Hash Maps (commonly just called “hashes” in Ruby) are the common key/value storage that we’ve used a lot at Turing so far, and not thought of to be node-based, but we’ll examine more about it in a moment.
If you want to research other data structures, here might be a good place to start.
Binary Tree
A binary tree is a type of data structure that organizes data in a way that allows for faster look-ups when searching through the data. There are 3 main operations that can be performed on the data: insertion, deletion, and search. The data is structured so that there is a root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
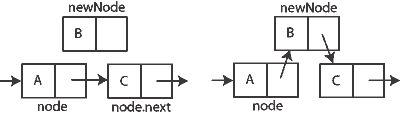 </details>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
Bubble Sort Visual</summary>
</details>
Think About It
- How long would it take to complete a bubble sort?
- Write pseudo code for how you might sort this array
[7, 3, 4, 9].
Pseudo Solution
Review Solution</summary>
- Starting Array [7, 3, 4, 9]
- Find length of Array
- Compare each adjacent element until end is reached
- Start with index 0 and continue until last index equals array
length -1
- If element with smaller index is greater swap elements
- Repeat process until array is sorted
</details>
Insertion Sort
Insertion sort is done by sectioning the list or array into sorted and unsorted sections. Elements are then taken from the unsorted section and inserted into the correct position in the sorted section. The current element is compared to the prior element. The value that is greater is then shifted forward to make room for the smaller element.
Insertion Sort Visual</summary>
</details>
Think About It
- How long would it take to complete an insertion sort?
- How does insertion sort compare to bubble sort?
Merge Sort
Merge sort takes the divide and conquer approach to sorting the list or array of elements. The array is continually split until only single elements of the array remain. Then the elements are compared to one another and merged in chunks. Once the elements have been broken into multiple single element arrays, the elements are then compared to make paired arrays. This process will continue by comparing the first element of the array to the first element of the other array until all the chunks are broken and combined to form a single array.
Merge Sort Visual</summary>
</details>
Think About It
- How long would it take to complete a merge sort?
- How does this sort compare to bubble and insertion?
Data Structures
A data structure encompasses how the data is organized, managed, and what actions can be performed on the data. There are multiple types of data structures in programming and in order to determine the type of structure to use you might start by asking the following questions:
- How does the data need to be stored?
- The size of the data might help determine the answer to this question.
- What is the relationship between the elements of the data?
- How is the data used? What type of operations need to be performed to the data?
We are only going to explore some data structures, binary tree, linked list, and hash maps.
Binary Trees and Linked Lists are both “node” based data structures, where each piece of data is a “node” which contains a value of some kind and a reference to one or more “next” nodes; the first node in a both is typically called the ‘head’ or ‘root’ node.
Hash Maps (commonly just called “hashes” in Ruby) are the common key/value storage that we’ve used a lot at Turing so far, and not thought of to be node-based, but we’ll examine more about it in a moment.
If you want to research other data structures, here might be a good place to start.
Binary Tree
A binary tree is a type of data structure that organizes data in a way that allows for faster look-ups when searching through the data. There are 3 main operations that can be performed on the data: insertion, deletion, and search. The data is structured so that there is a root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
 </details>
</details>[7, 3, 4, 9].
Review Solution</summary>
- Starting Array [7, 3, 4, 9]
- Find length of Array
- Compare each adjacent element until end is reached
- Start with index 0 and continue until last index equals array
length -1
- If element with smaller index is greater swap elements
- Repeat process until array is sorted
</details>
Insertion Sort
Insertion sort is done by sectioning the list or array into sorted and unsorted sections. Elements are then taken from the unsorted section and inserted into the correct position in the sorted section. The current element is compared to the prior element. The value that is greater is then shifted forward to make room for the smaller element.
Insertion Sort Visual</summary>
</details>
Think About It
- How long would it take to complete an insertion sort?
- How does insertion sort compare to bubble sort?
Merge Sort
Merge sort takes the divide and conquer approach to sorting the list or array of elements. The array is continually split until only single elements of the array remain. Then the elements are compared to one another and merged in chunks. Once the elements have been broken into multiple single element arrays, the elements are then compared to make paired arrays. This process will continue by comparing the first element of the array to the first element of the other array until all the chunks are broken and combined to form a single array.
Merge Sort Visual</summary>
</details>
Think About It
- How long would it take to complete a merge sort?
- How does this sort compare to bubble and insertion?
Data Structures
A data structure encompasses how the data is organized, managed, and what actions can be performed on the data. There are multiple types of data structures in programming and in order to determine the type of structure to use you might start by asking the following questions:
- How does the data need to be stored?
- The size of the data might help determine the answer to this question.
- What is the relationship between the elements of the data?
- How is the data used? What type of operations need to be performed to the data?
We are only going to explore some data structures, binary tree, linked list, and hash maps.
Binary Trees and Linked Lists are both “node” based data structures, where each piece of data is a “node” which contains a value of some kind and a reference to one or more “next” nodes; the first node in a both is typically called the ‘head’ or ‘root’ node.
Hash Maps (commonly just called “hashes” in Ruby) are the common key/value storage that we’ve used a lot at Turing so far, and not thought of to be node-based, but we’ll examine more about it in a moment.
If you want to research other data structures, here might be a good place to start.
Binary Tree
A binary tree is a type of data structure that organizes data in a way that allows for faster look-ups when searching through the data. There are 3 main operations that can be performed on the data: insertion, deletion, and search. The data is structured so that there is a root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
Insertion Sort Visual</summary>
</details>
Think About It
- How long would it take to complete an insertion sort?
- How does insertion sort compare to bubble sort?
Merge Sort
Merge sort takes the divide and conquer approach to sorting the list or array of elements. The array is continually split until only single elements of the array remain. Then the elements are compared to one another and merged in chunks. Once the elements have been broken into multiple single element arrays, the elements are then compared to make paired arrays. This process will continue by comparing the first element of the array to the first element of the other array until all the chunks are broken and combined to form a single array.
Merge Sort Visual</summary>
</details>
Think About It
- How long would it take to complete a merge sort?
- How does this sort compare to bubble and insertion?
Data Structures
A data structure encompasses how the data is organized, managed, and what actions can be performed on the data. There are multiple types of data structures in programming and in order to determine the type of structure to use you might start by asking the following questions:
- How does the data need to be stored?
- The size of the data might help determine the answer to this question.
- What is the relationship between the elements of the data?
- How is the data used? What type of operations need to be performed to the data?
We are only going to explore some data structures, binary tree, linked list, and hash maps.
Binary Trees and Linked Lists are both “node” based data structures, where each piece of data is a “node” which contains a value of some kind and a reference to one or more “next” nodes; the first node in a both is typically called the ‘head’ or ‘root’ node.
Hash Maps (commonly just called “hashes” in Ruby) are the common key/value storage that we’ve used a lot at Turing so far, and not thought of to be node-based, but we’ll examine more about it in a moment.
If you want to research other data structures, here might be a good place to start.
Binary Tree
A binary tree is a type of data structure that organizes data in a way that allows for faster look-ups when searching through the data. There are 3 main operations that can be performed on the data: insertion, deletion, and search. The data is structured so that there is a root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
 </details>
</details>
Merge Sort Visual</summary>
</details>
Think About It
- How long would it take to complete a merge sort?
- How does this sort compare to bubble and insertion?
Data Structures
A data structure encompasses how the data is organized, managed, and what actions can be performed on the data. There are multiple types of data structures in programming and in order to determine the type of structure to use you might start by asking the following questions:
- How does the data need to be stored?
- The size of the data might help determine the answer to this question.
- What is the relationship between the elements of the data?
- How is the data used? What type of operations need to be performed to the data?
We are only going to explore some data structures, binary tree, linked list, and hash maps.
Binary Trees and Linked Lists are both “node” based data structures, where each piece of data is a “node” which contains a value of some kind and a reference to one or more “next” nodes; the first node in a both is typically called the ‘head’ or ‘root’ node.
Hash Maps (commonly just called “hashes” in Ruby) are the common key/value storage that we’ve used a lot at Turing so far, and not thought of to be node-based, but we’ll examine more about it in a moment.
If you want to research other data structures, here might be a good place to start.
Binary Tree
A binary tree is a type of data structure that organizes data in a way that allows for faster look-ups when searching through the data. There are 3 main operations that can be performed on the data: insertion, deletion, and search. The data is structured so that there is a root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
 </details>
</details>- The size of the data might help determine the answer to this question.
root node, the starting point, and each node can point to two other nodes. In order to traverse the tree for a search, the element is compared to a node and determined whether it is greater than, less than, or equal to the element.
Binary Tree Search Compared to a Sorted Array Visual </summary>
</details>
A Binary Tree gets it’s “binary” name from the notion that each “node” points to two other nodes, typically programmed as a “left” and a “right” node.
Think About It
- When might a binary tree be a beneficial structure to use?
- Why is it more advantageous to use a binary tree than an array?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and binarytree.rb will go in a lib/ folderbinary_tree_test.rb will go in a test/ folder
- Write some code to make the tests pass
Linked List
A linked list is a data structure that organizes the data as a linear collection (like a binary tree, but it doesn’t branch into left/right). However, unlike arrays, linked lists do not need to be stored with the data all together in memory. It is able to achieve this because each node contains the element data (value) and a reference to the “next” node in the list. Linked list operations include appending, deleting, and inserting data. There are also different types of linked lists: singly linked, doubly linked, and circularly linked.
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
node.rbandbinarytree.rbwill go in alib/folderbinary_tree_test.rbwill go in atest/folder
Singly Linked List Example</summary>
</details>
Think About It
- What is the advantage of using a linked list?
- What is the difference between a singly linked, doubly linked, and circularly linked list?
Work to do:
- Open this gist and copy the contents into an appropriate folder structure:
node.rb and linkedlist.rb will go in a lib/ folderlinked_list_test.rb will go in a test/ folder
- Write some code to make the tests pass
Hash Maps
Hashes, at a high level are “key-value” data structures, but how do they actually work?
The “hash” name comes from a mathematical formula about how the hash knows where to store each piece of data in memory. The more complex a “hashing” algorithm is, the more easily things can be stored into “unique” places in memory, but will take longer to actually do the calculation. Less-complex hashing algorithms are much faster, but risk more “collisions” of data. (eg, if our “hashing” algorithm was only storing strings, and we used the first letter of the string to define where it was put in memory, and our strings were student names, then “James”, “Jamal”, “Jackie”, etc would all “collide” in memory.
So, hash maps use an array (commonly referred to as “buckets”), where each “bucket” is a “head” node of a linked list. Back to our “student names” example, we’d have 26 “buckets”, one for each letter of the alphabet, and the “J” bucket would be a linked list where each node contains the names for James, Jamal, Jackie, etc.. This is the “map” explanation of the name of “hash map”, it’s using a “hash” algorithm to generate a “map” of where things get stored in memory. You might also hear the term “hash table”.
In a typical Hash Map, if there’s a “collision” (ie, the letter “J”), every value is shifted to the right and the newer data is stored as the new start of that bucket’s linked list.
The main difference with this linked list, though, is that a hash has a name and a value.
In our students example, we might want to store the ages of our students like this:
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
Since our Linked List only has a value, if we just stored “27”, “31”, and “29”, we would lose track of which student had which age. So now our Hah Map’s Linked List “node” has to be a little more advanced. We have to store the original “key” value, plus that key’s “value” (in this example, the student age).
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
When we want to recall a student’s age, say Jamal, we run our hash algorithm on the “key” (“Jamal”), which would produce our “J” value, go to our “J” bucket, and then traverse that linked list until we find a node which has a payload which includes a “key” attribute with “Jamal” in it, and then return the “value”.
Work to do:
- Build some Ruby code that does a very rudimentary “hashing” algorithm for a given string that just returns the first letter of the string, something like this should suffice:
def hash(string)
string[0]
end
- Make an array of 26 Linked Lists, one for each letter of the alphabet, and write some code to insert and retrieve some key/value pairs from your hash.
- Hint: the word “Hash” will be reserved in Ruby, so call it something else
Looking for More?
This repo has several computer science exercises to deepen your understanding.
 </details>
</details>
Think About It
node.rbandlinkedlist.rbwill go in alib/folderlinked_list_test.rbwill go in atest/folder
{
'James': 27,
'Jamal': 31,
'Jackie': 29,
etc
}
class Node
attr_reader :key, :value
attr_accessor :next
def initialize(key, value)
@key = key
@value = value
@next = nil
end
end
def hash(string)
string[0]
end